
ACE-Step 1.5 Explained
The ACE-Step 1.5 paper can be confusing. Here are its main ideas.

Main components:
DIFFUSION MODEL: supports multiple tasks such as generation, remixing, and editing.
LANGUAGE MODEL: supports reprompting and semantic tokens generation.
DATA PREPARATION: detailed annotation of 27M songs.
OPEN WEIGHTS: a range of models is available, with support for LoRA fine-tunes.
How does it work?
First, ACE-Step 1.5 relies on the LANGUAGE MODEL to generate structured metadata (e.g., genre, instruments, mood, structure) from unstructured user prompts.
In a second pass, the same LANGUAGE MODEL generates semantic tokens conditioned on the above described metadata.
The authors refer to these two stages as “chain-of-thought” or “planning” or “structuring the music” before the audio is generated.
Important: The LANGUAGE MODEL generates both text tokens (first pass) and semantic tokens (second pass).
Finally, the (LATENT) DIFFUSION MODEL generates 48 kHz stereo audio.
Depending on its configuration, the DIFFUSION MODEL can perform text-to-music generation, cover generation, continuations, or instrument addition/removal.
Diffusion Model
The generative model is a LATENT diffusion model with these components:
CONVOLUTIONAL VAE: compresses 48kHz stereo audio into a compact 64-dimensional latent at 25Hz, trained with an adversarial objective.
DIFFUSION TRANSFORMER: with odd layers using sliding window attention to capture local features, while even layers use global group query attention to model long-term structure.
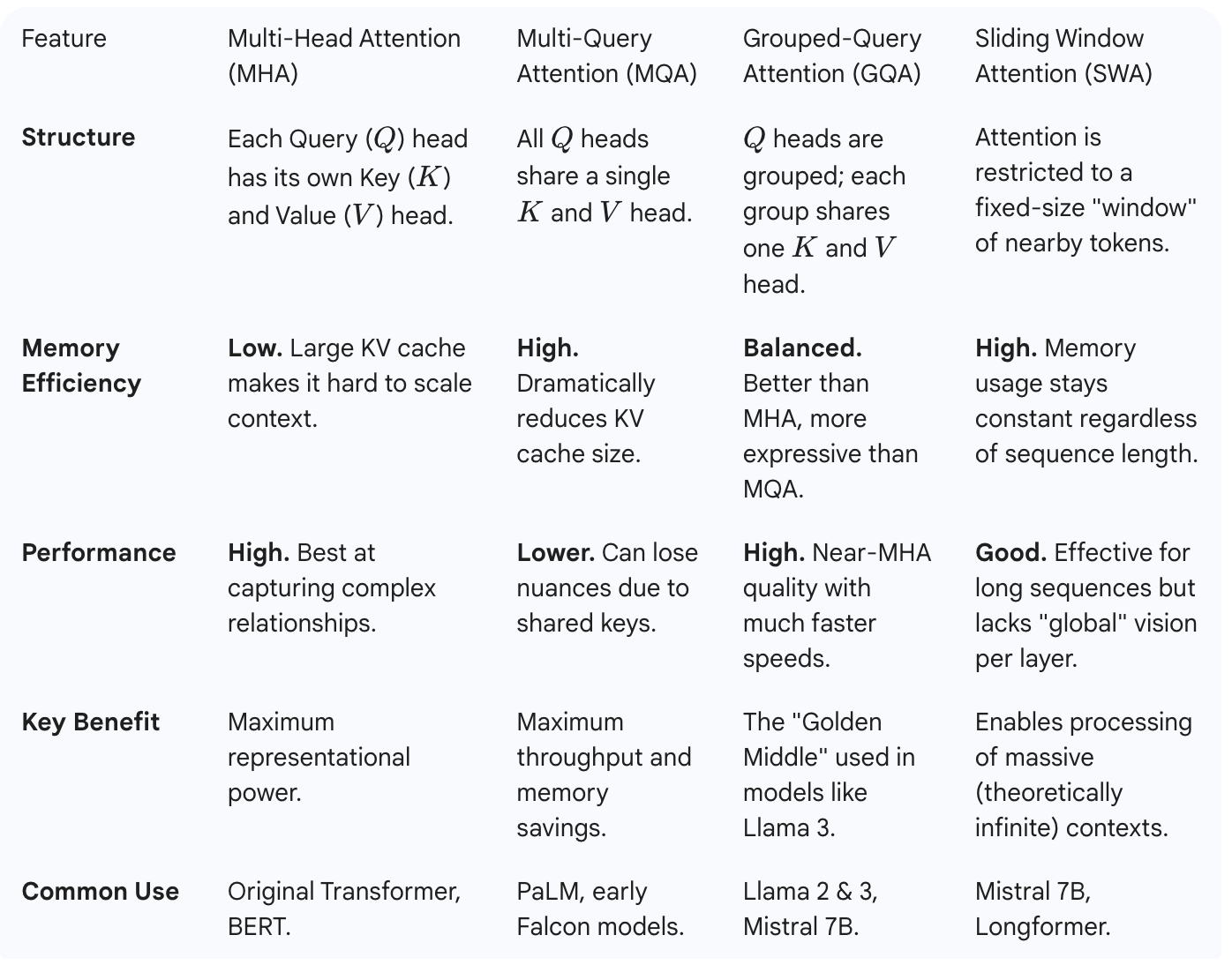
It is conditioned on:
Caption embeddings, produced by a frozen Qwen3-0.6B model.
Timbre and lyric encoders, trained jointly with the system.
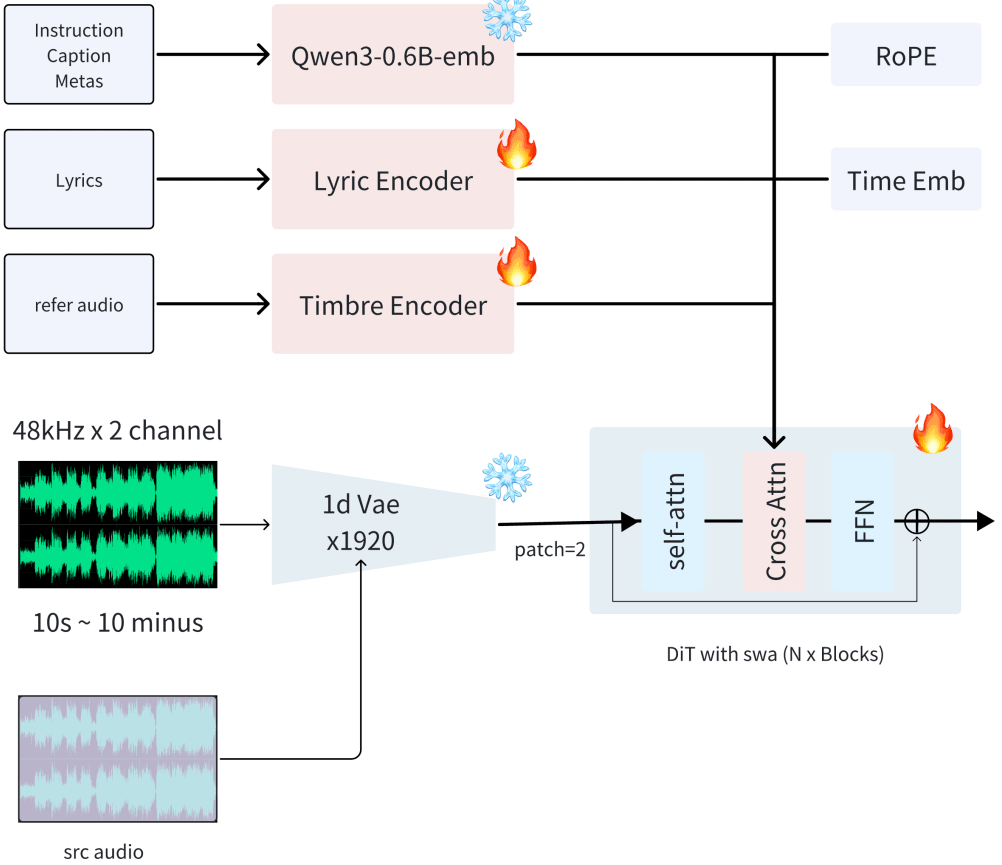
ACE-Step 1.5 can handle multiple tasks simultaneously, including: text-to-music, cover generation, repainting, vocal-to-background separation, track extraction, or layer addition. To that end, the model processes multiple inputs:
SOURCE: latent of the audio to generate/edit.
NOISED TARGET: required input for diffusion.
MASK: defines structure, required for repainting.
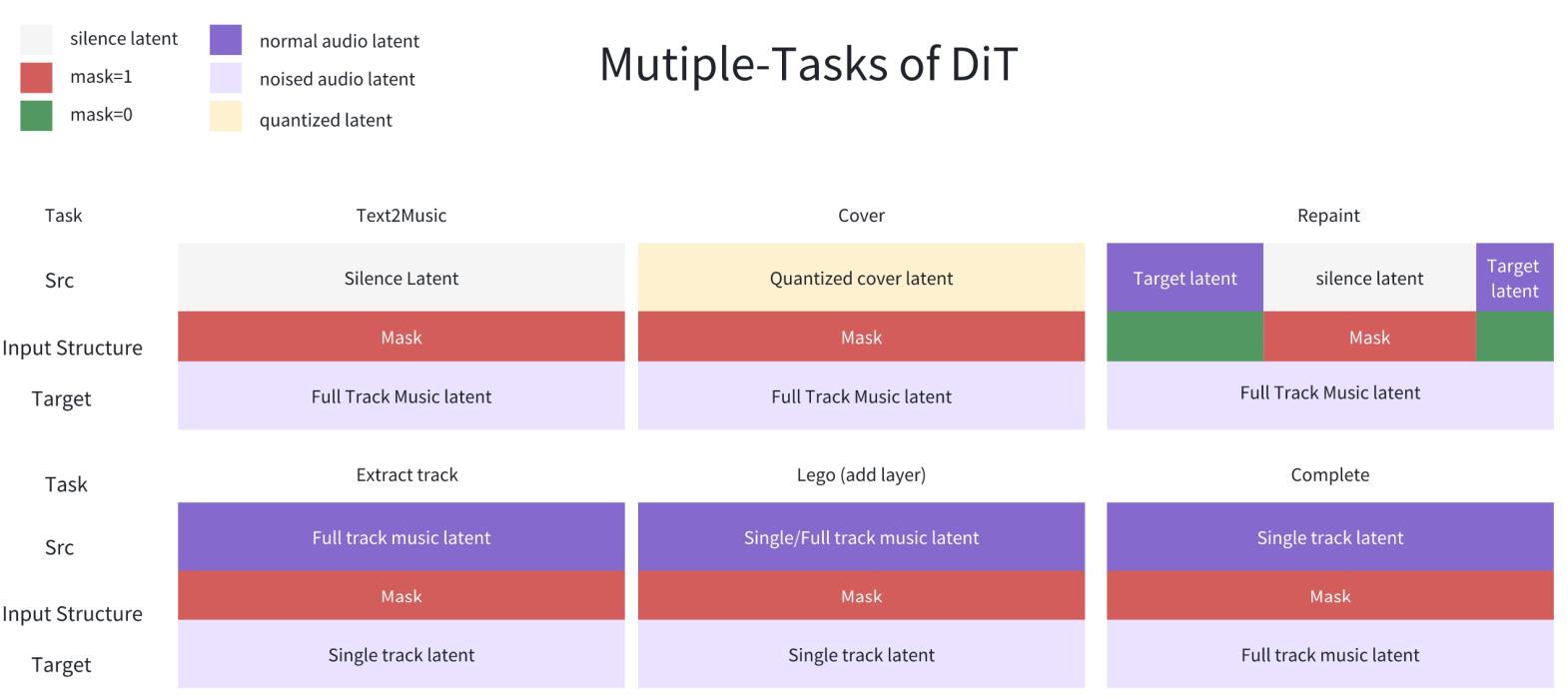
Training proceeds as follows:
Pre-training with 20M text-to-music pairs.
Multi-task fine-tuning with best 10M songs and 6M stem-separated tracks.
High quality fine-tuning with a subset of 2M songs.
Few-step distillation, for fast inference (from 50 diffusion steps to 8).
“Intrinsic” reinforcement learning (DiffusionNFT) that does not rely on human preferences.
Few-step distillation is based on distribution matching distillation (DMD2) plus adversarial training.
The “intrinsic” reinforcement learning algorithm is interesting as it does not require training an additional reward model nor human preferences.
Instead, it uses the consensus across multiple cross-attention heads (between lyrics tokens and latent-audio frames) as a reward signal for lyric-audio synchronization:
High consensus → sharp, coordinated attention peaks across heads → high alignment scores.
Low consensus → blurry, scattered attention patterns → low alignment scores.
Traditional RL for diffusion models requires traversing the full denoising path to compute a reward. In contrast, DiffusionNFT leverages intermediate steps, eliminating the need to traverse the entire path.
Language Model
Remember that prompt interpretation is handled by the language model, while the diffusion model focuses on audio generation.
From unstructured user prompts, the language model generates structured YAML metadata (e.g., BPM, key, duration, and song structure).
By offloading prompt understanding to the language model, the system ensures the DiT receives clear, unambiguous conditioning, maximizing its generative potential.
In addition, the language model generates “semantic tokens”. The authors refer to these as “audio codes”, but given their very low temporal resolution (5 Hz), I refer to them as “semantic tokens” to remain consistent with previous works.
Semantic tokens are obtained by downsampling latent representations using an attention pooler, followed by quantization with finite scalar quantization (FSQ).
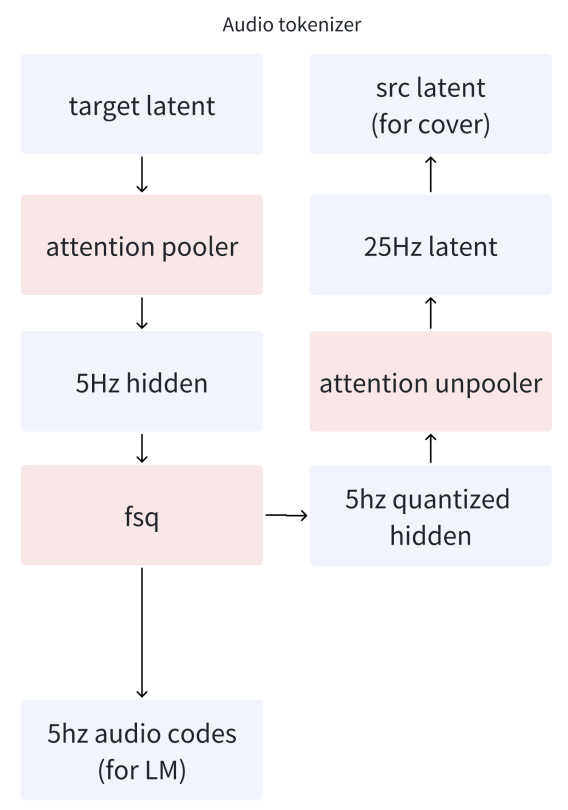
Training proceeds as follows:
Train the audio tokenizer to get semantic tokens (“audio codes”).
Pre-training from Qwen3 models.
Supervised fine-tuning.
“Intrinsic” reinforcement learning (GRPO) that does not rely on human preferences.
Note that the original language model operates only on text tokens. Through pre-training, supervised fine-tuning, and reinforcement learning, the language model learns to handle semantic tokens (5 Hz “audio codes”). For example:
Text-to-tokens: given text captions, it generates semantic tokens.
Tokens-to-text: given semantic tokens, it predicts the corresponding captions.
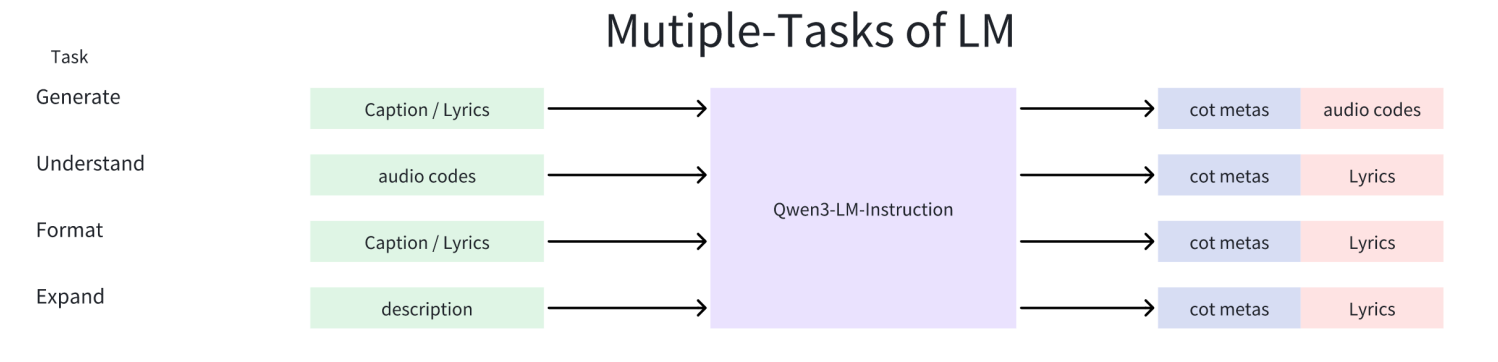
During RL, this bidirectional capability (text-to-tokens and tokens-to-text) allows designing a self-consistency reward without requiring an external reward model.
The reward is based on pointwise mutual information (PMI), which penalizes generic descriptions and rewards captions that are specific to the given semantic tokens.
PMI = log P(condition|codes) - log P(condition)
Generative Reward Policy Optimization (GRPO) generates multiple outputs for the same prompt, ranks them by reward (PMI scores), and updates the policy using relative comparisons within the group.
Samples better than the group average get reinforced and worse ones get suppressed, eliminating the need for a separate critic network.
Data Preparation
Annotate 5M audios with Gemini 2.5.
Fine-tune Qwen2.5-Omni to create ACE-Captioner.
Fine-tune Qwen2.5-Omni to create ACE-Transcriber. This is used to transcribe lyrics.
Reward model used to further train ACE-Captioner and ACE-Transcriber with reinforcement learning.
Use ACE-Captioner and ACE-Transcribe to caption and transcribe the lyrics of 27M songs.
Reward model to discart low-alignement pairings.
Open Weights
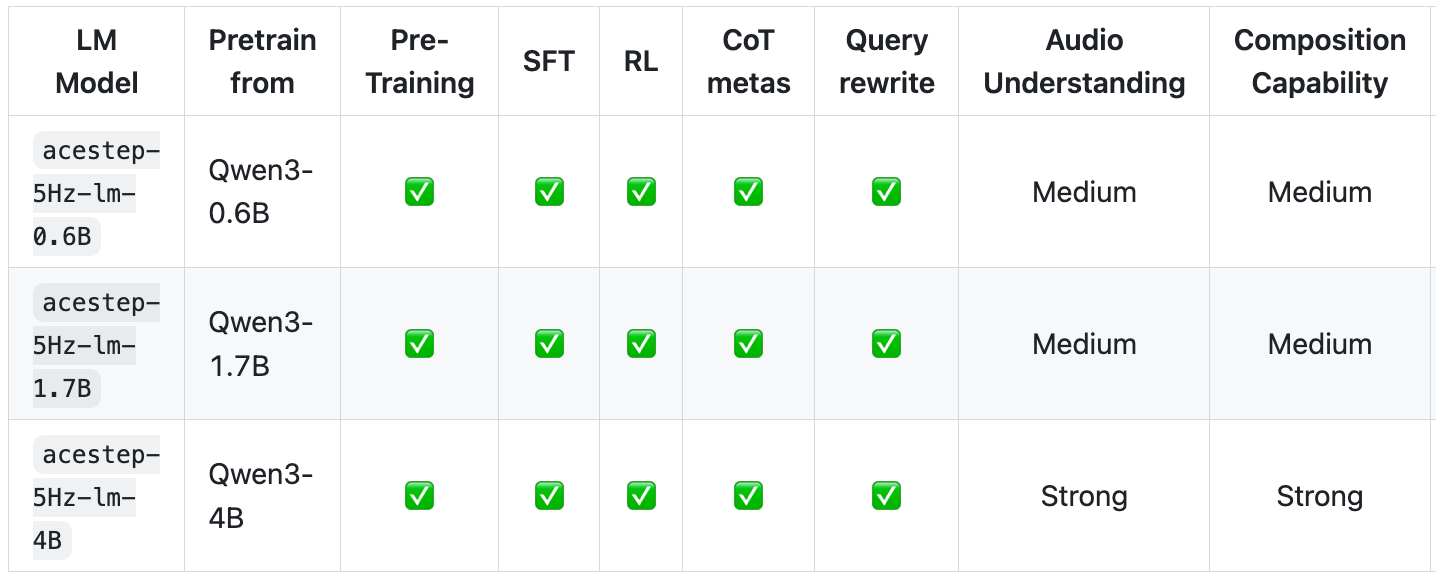
Several different models have been made available.
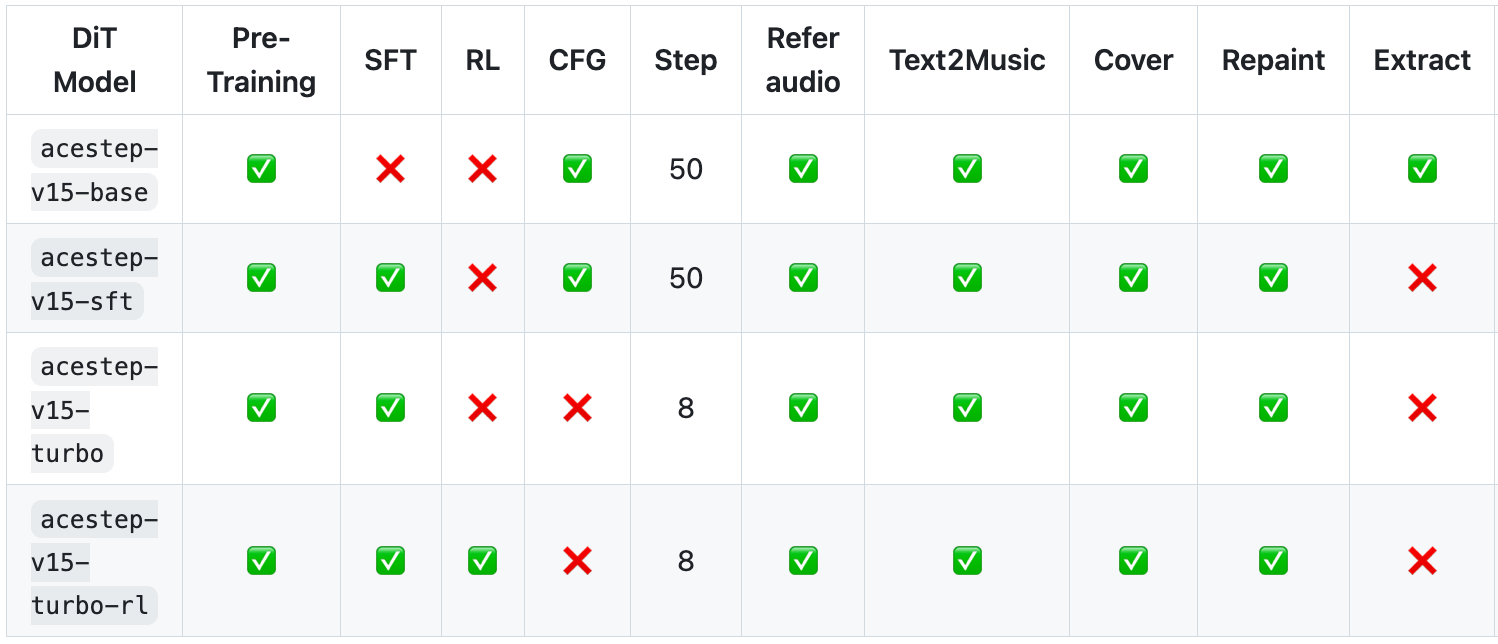
The distilled turbo models are fast, generating a full song in just 2 seconds on an A100 and under 10 seconds on an RTX 3090.
They can also run locally on machines with less than 4 GB of VRAM.
ACE-Step 1.5 also supports LoRA fine-tuning, allowing users to easily personalize the model for their own audio or style preferences.
Disclaimer. The paper provides limited implementation details. To better understand the underlying methodology, I studied both the paper and the released codebase. Yet, the reinforcement learning components, parts of the training pipeline, and the training data are not publicly available. I welcome feedback or corrections if others understand parts of ACE-Step 1.5 differently. The views expressed are do not reflect the opinions or positions of my employer.