
HeartMuLa Explained
Does HeartMuLa outperform Suno in music generation?

HeartMuLa is an open-source music model that claims to perform on par with Suno.
It consists of 4 components:
1. HeartCodec: low-rate audio tokens.
2. HeartMuLa: autoregressive generative model.
3. HeartTranscriptor: lyrics tokens.
4. HeartCLAP: text and reference-audio tokens.
1. HeartCodec
HeartCodec compresses audio (48 kHz) into tokens at a low rate (12.5 Hz).
It operates at a low rate, which is crucial for generating long music sequences. A lower rate means fewer tokens need to be generated, making the process more efficient.

Let’s go through the HeartCodec diagram, following the colored blocks.
Yellow. It leverages semantic representations across multiple abstraction levels:
- MuEncoder → musical (layer 11) and acoustic (layer 2) embeddings.
- WavLM and Whisper → two different phonetic embeddings.
Purple. The downsampling schema is based on insert/extract query. After every two consecutive frames, a learnable query token is inserted. Then, the two consecutive frames are extracted (removed). This reduces the frame rate by two and produces a downsampled representation which is then discretized using residual vector quantization (RVQ).
Blue. Each “Layer” (from 0 to K-1) represents one of the K RVQ codebooks.
Green. A two-step decoder is used to turn RVQ tokens into waveforms:
- Flow matching generating SQ-Codec continuous latents.
- SQ-Codec decoder generating waveforms.
HeartCodec is trained in 3 stages:
- Pre-training and finetuning with 600k songs.
- Reflow Distillation with 50k high-quality songs.
- Finetuning the SQ-Codec decoder.
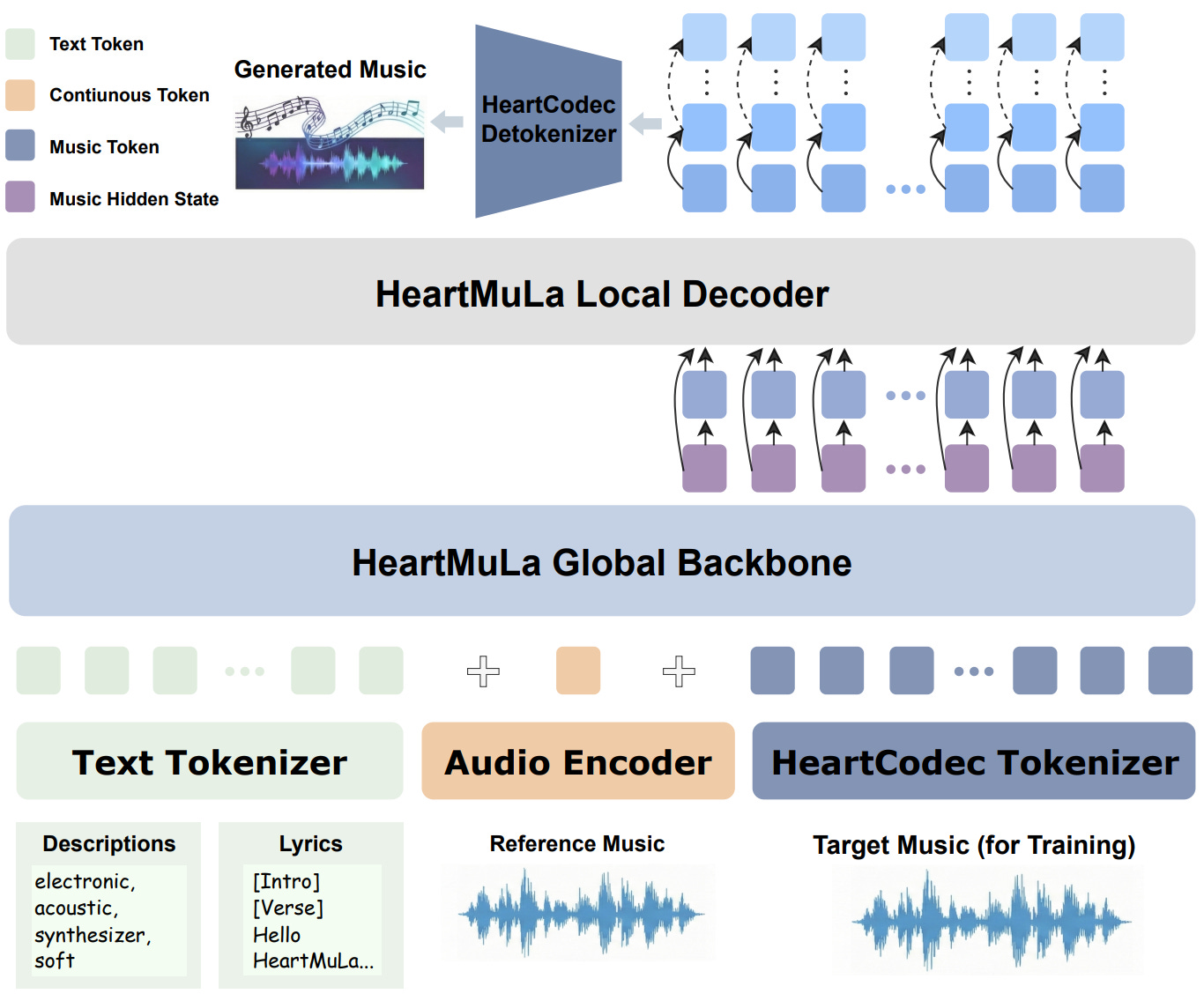
2. HeartMuLa
HeartMuLa is an autoregressive generative model, and it’s hierarchical.
It operates on discrete audio tokens produced by HeartCodec and is conditioned on:
- Tags.
- Lyrics.
- Reference audio.
RVQ consists of K codebooks, and the K=0 one captures the coarse “semantic” information. The rest of residual layers, provide acoustic details. The hierarchical structure of the model exploits this fact, to predict first all K=0 tokens (first global step) and then predict the rest of the tokens (second local step).
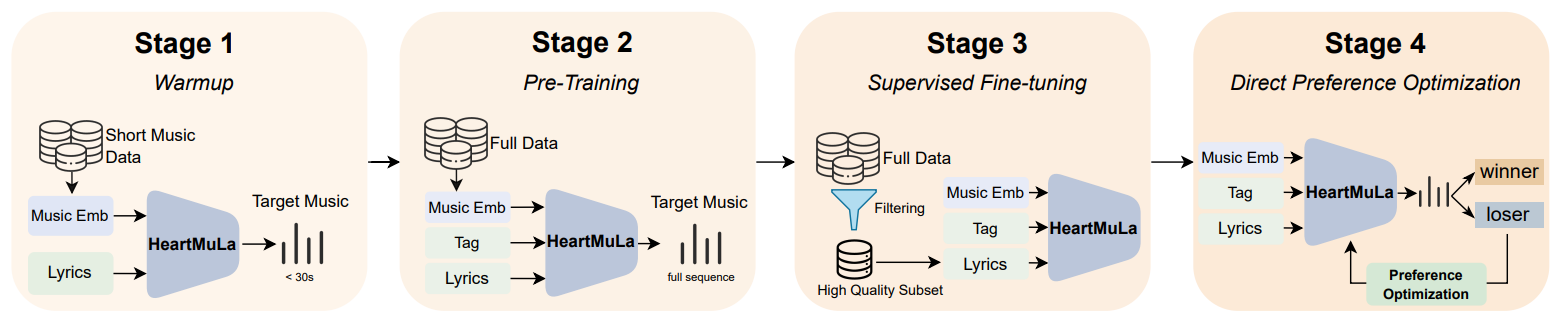
Training involves 4 stages:
- Warmup with 30 sec segments.
- Pretraining with full songs.
- Supervised Finetuning with high-quality subset.
- Direct Preference Optimization (DPO).
DPO reformulates the RL objective as supervised learning, optimizing the policy directly from preference pairs without needing a reward model.
3. HeartTranscriptor
HeartTranscriptor is a lyric recognition model optimized for musical audio. It is a fine-tuned version of Whisper trained on the high-quality dataset of music recordings.
4. HeartCLAP
HeartCLAP consists of two main components: a text encoder and a music encoder. Both are initialized with pre-trained weights from MuQ-MuLan and are used to extract text and reference-audio tokens.
Dataset
It consists of three parts: music with lyrics, instrumental music, and TTS datasets, totaling around 600k songs and 50k segments (about 100k hours) of high-quality audio.
HeartTranscriptor was used to align lyrics with the music.
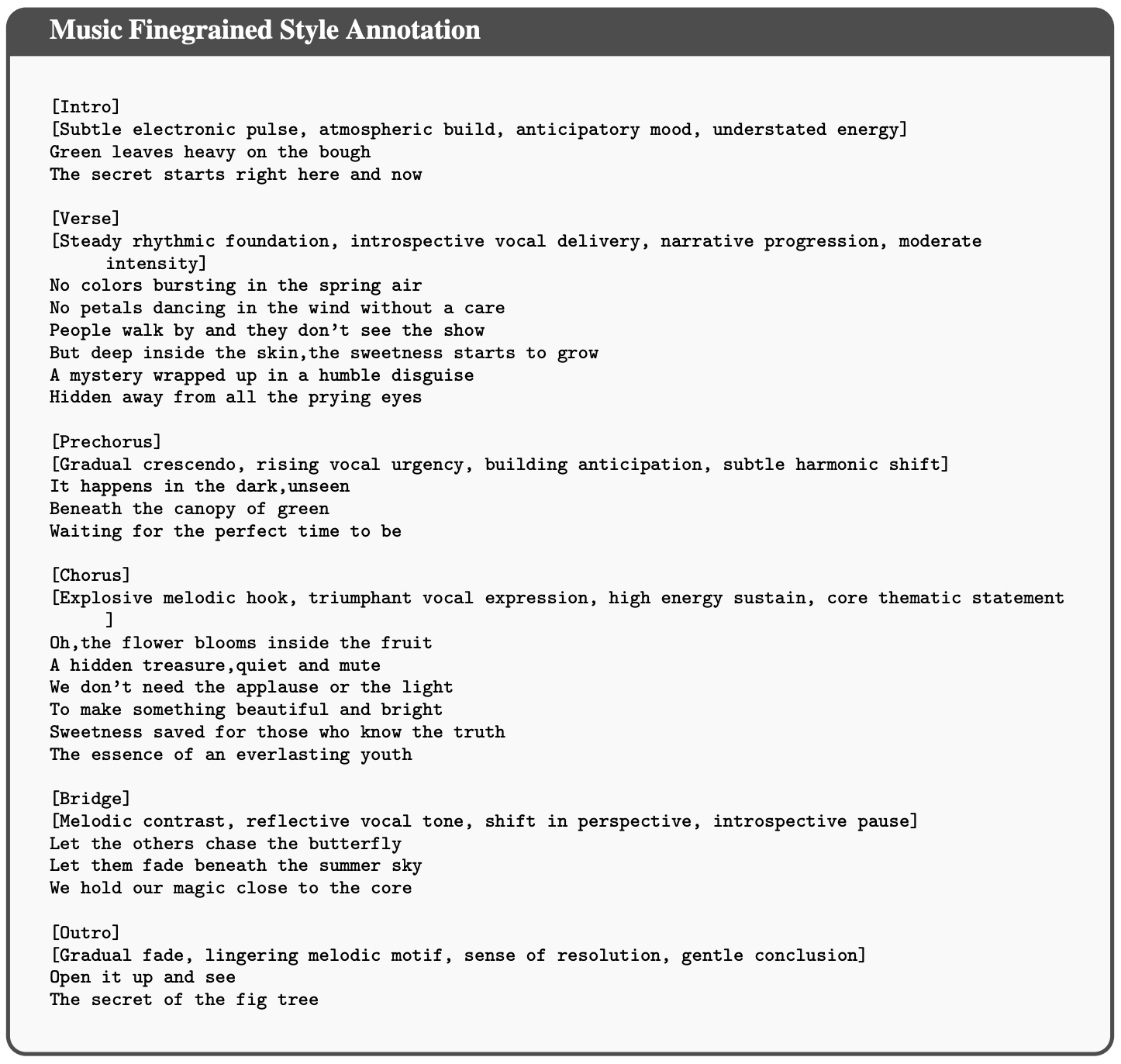
SongFormer was used to annotate the music’s structure and sections, with prompts defined at the section level.
Tags were generated using Qwen2.5-Omni.
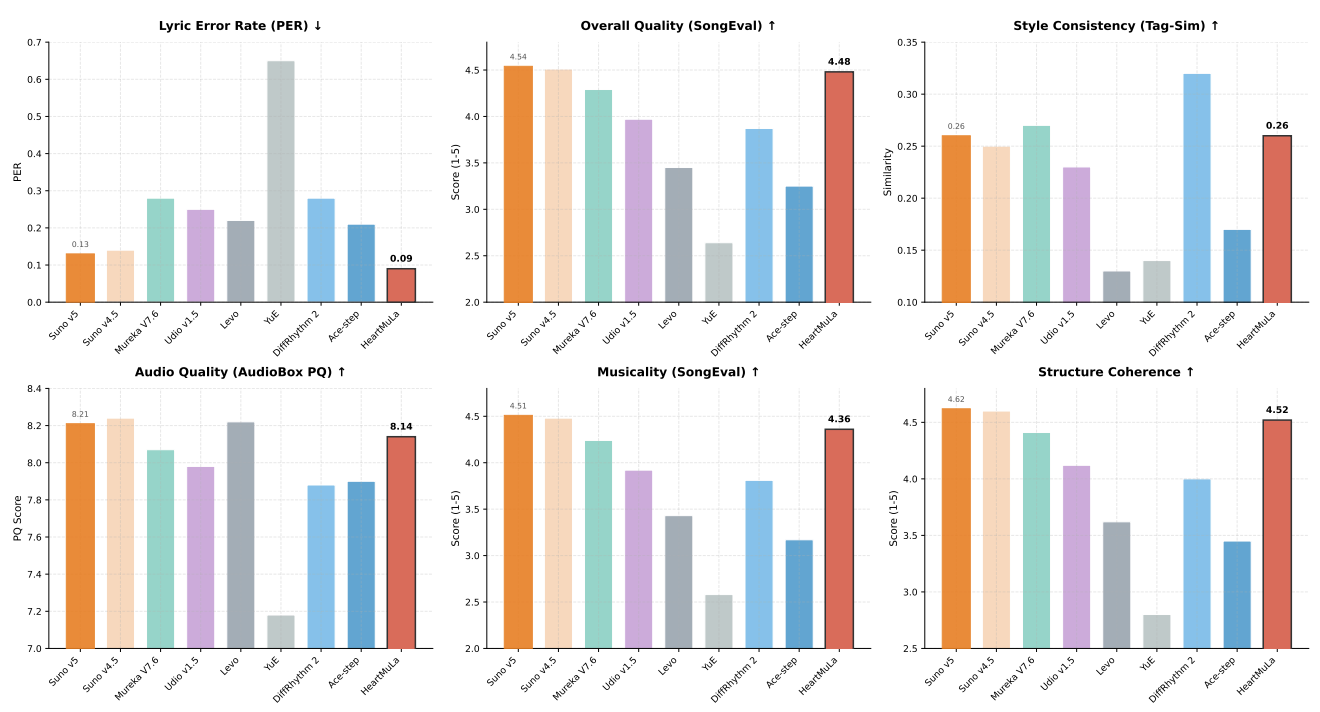
Results
The abstract claims to “reproduce a Suno-level, commercial-grade system using academic-scale data and GPU resources”.
And the results show it is pretty close, congrats to the team!
Disclaimer. The views expressed are my own and do not reflect the opinions or positions of my employer.
Want to try HeartMuLa but don't want to deal with manual setup, dependencies, and config files? Check out HeartMuse — an open-source web UI that streamlines the whole AI music creation process.
Getting started is painless — ./install.sh and ./run.sh is all you need. The installer handles the virtual environment, dependencies, and HeartMuLa library setup automatically. Models download from Hugging Face on first use. No manual config, no dependency headaches.
Describe the song you want (e.g. "energetic summer pop about traveling"), and HeartMuse uses an LLM to generate lyrics, a title, and music tags — then feeds them into HeartMuLa to produce the audio. Everything in one interface. Works with Ollama (fully local, nothing leaves your machine) or OpenAI API — switch between them with one click.
You get full creative control: let AI generate everything from scratch, write your own chorus and let AI add verses around it, or write full lyrics and just have AI suggest tags and a title. Every field has its own generate checkbox — mix and match however you like.
GitHub: https://github.com/strnad/heartmuse
Feedback welcome!