
LatCHs Explained
LatCHs are Latent-Control Heads, and is our latest paper.

Fine-grained control in creative workflows drives demand for controllable music and audio generation.
But recently proposed models require supervised TRAINING or FINETUNING with data that is challenging to collect.
Given the high costs of training or finetuning generative models, INFERENCE-TIME control methods have been introduced.
We explore inference-time controls through a “guidance-based” approach that relies on “selective TFG” and “Latent-Control Heads (LatCHs)”.
Guidance? Use the gradient of a target distance function with respect to the diffusion process to guide sampling. For example, use RMS to guide sampling.
Selective TFG? Only apply TFG to a few early steps. TFG is a type of guidance that unifies most guidance-based frameworks, see below.
Latent-Control Heads (LatCHs)? Audio-based guidance is costly because it requires backpropagation through audio decoders during sampling. We instead train latent-control heads to guide diffusion through latent features directly.
TL;DR: LatCHs guide the diffusion process directly in latent space, avoiding the expensive decoder step, and requiring minimal training resources (7M parameters and ≈ 4 hours of training). Experiments with Stable Audio Open demonstrate effective control over intensity, pitch, and beats (and a combination of those) while maintaining generation quality. We are the first to use latent-control heads for guidance in few, selected diffusion steps.
Latent-Control Heads (LatCHs)
Guidance-based methods rely on a pretrained latent diffusion model and introduce an external control signal (e.g., RMS) that the model was not explicitly trained to follow.
To enforce this control, such methods compute the gradient of a target signal (e.g., RMS) with respect to the diffusion process and use it to guide sampling.
End-to-end guidance can be slow and VRAM intensive as it requires backpropagating through the VAE decoder.
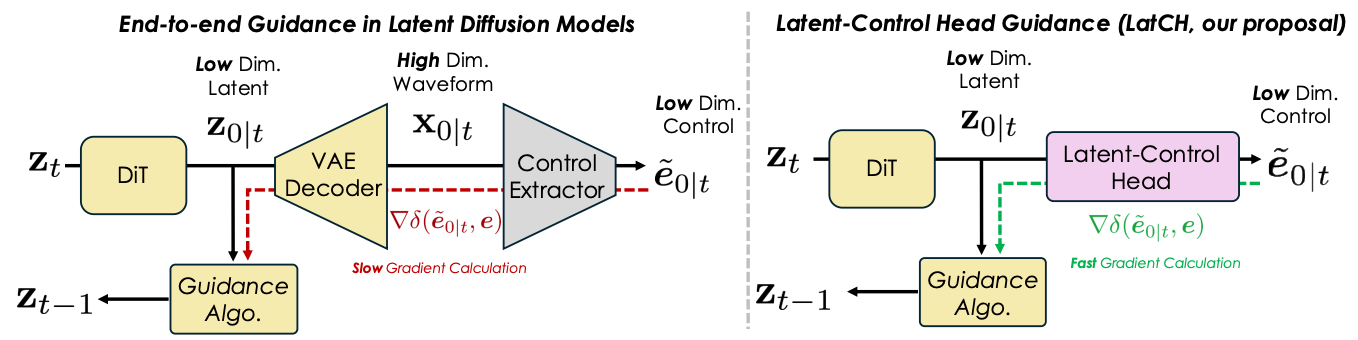
LatCHs, however, are compute-efficient because they directly predict control features from the latent space. There is no need to decode latents into audio.
TFG
Our work uses TFG as the guidance method.
TFG unifies most guidance-based frameworks (DPS, MPGD, LGD, UGD) within a shared hyperparameter space:
Guidance strength (ρ and µ).
Guidance accuracy strength (γ, controlled by adding noise).
Niter and Nrecur, which define how many times guidance is applied.
If ρ or µ are too high, the sampling process may drift off-manifold. Keeping ρ and µ small preserves output quality while still following the control signal.
We found that increasing γ was crucial in some cases. When guidance follows the control too aggressively, audio quality may degrade (off-manifold drift). While reducing ρ or µ could weaken control adherence, increasing γ provides an alternative way to relax guidance precision while preserving both audio quality and control.
TFG is compatible with CFG scaling, which we set to 7.
Note: TFG stands for Training-Free Guidance. While TFG itself is training-free, we additionally train Latent-Control Heads.
Selective TFG
One key factor omitted from TFG’s hyperparameter space is which diffusion steps to apply guidance.
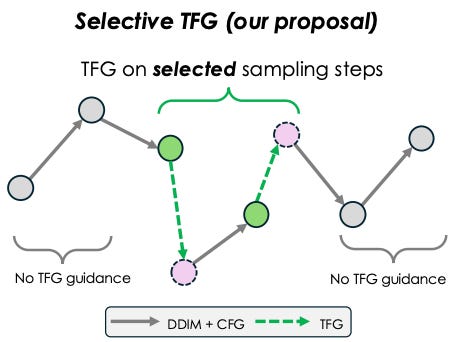
Since a control signal may perceptually arise at specific points during sampling, limiting guidance to those steps reduces the risk of drifting off-manifold.
By applying TFG guidance only on a few selected steps, we reduce computational overhead while balancing control accuracy and audio quality.
Applying guidance to more steps improves control alignment but increases the risk of drifting off-manifold.
Applying guidance to fewer steps reduces drift risk but may weaken control precision.
We call this selective TFG, where guidance is applied only to a subset of steps. In our experiments, we use guidance on just 20% of the early sampling steps.
Results
We explored intensity (RMS), beat-tracking, pitch (CREPE), tags (PANNs) and harmony (chroma) as control features.
LatCHs achieve competitive performance in audio quality, prompt adherence, control alignment, and efficiency.
End-to-end also performs well, but at a high compute cost.
MOS results are generally good for beats and intensity, and those quality metrics are comparable to SAO.
Multiple guidance controls also works (e.g., beats+intensity).
The studied methods are more reliable with gradual or low-frequency controls, such as intensity or beats.
Controls with greater variability, such as pitch, which involves rapid note changes, pose challenges, and show worse performance across quality metrics.
Note that intensity and beats consist of 1D outputs and pitch outputs 160 pitch classes. We also explored PANNs (527 tags) and Chroma (12 pitches) feature extractors with mixed results. Based on those observations, we hypothesize that 1D outputs, rather than sparse high-dimensional ones, could be more suited for guidance.