
Latent Diffusion in AI Art
Understanding diffusion, latent spaces, and their impact on AI-generated art.

Latent diffusion dominates generative AI, powering audio, image, and video generation.
But what’s diffusion?
It transforms noise into coherent images or media.
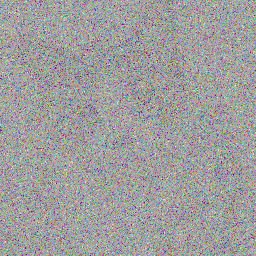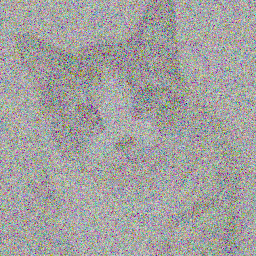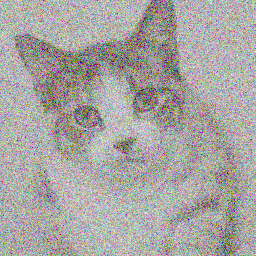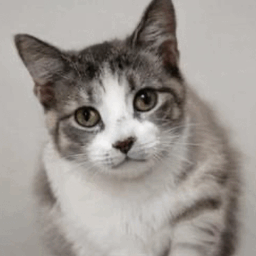
From noise to media, diffusion refines the output image with each step.
But what’s latent diffusion?
The same as diffusion, but applied to latents instead of images. Refining latents with each step.
Aaaand.. what’s a latent?
A compact, representation of data.
Latents represent the essence of an image or media, compressed into a smaller, more abstract space from which the original media can be reconstructed.
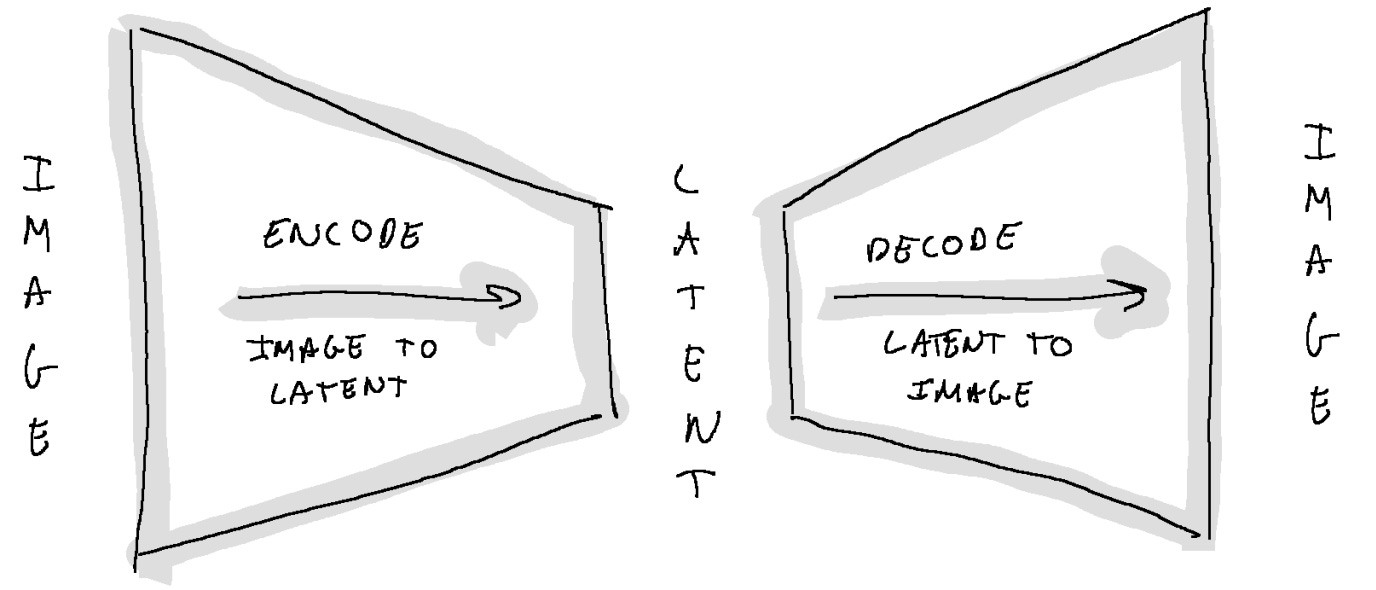
It operates in a compressed latent space rather than directly on images, which reduces computational load.
Faster. Lighter.
How We Got Here
Latent diffusion is now widely used, but GANs and autoregressive models have also been crucial.
Generative Adversarial Networks (GANs) use a "generator" to create content and a "discriminator" to detect if it’s real or generated. They improve adversarially, with the "generator" creating better content to deceive the "discriminator."
Autoregresive models generate the next value in a sequence based on previous ones, one step at a time. Such models can work with raw media (pixels, waveform samples) or latent representations.

On Audio Generation
2016: WaveNet introduced autoregressive modeling for waveforms.
2019: Adversarial Audio Synthesis successfully applied GANs to audio.
2020: Jukebox introduced latent autoregressive models with transformers.
2022: AudioLM made latent autoregressive modelling work.
2024: Stable Audio applied latent diffusion for efficient text-to-music and -audio.
Autoregressive models are also popular in audio, alongside latent diffusion.
But latent diffusion is fast. And can run on-device. This lets you "prompt jockey" (as opposed to “disk jockey”) in a club with tracks that don’t yet exist. No internet required.
On Image Generation
2014: Ian Goodfellow et al. introduced GANs, which once dominated image generation.
2017: Progressive GAN generates high-resolution, photo-realistic images.
2018: BigGAN scaled up GANs for high-quality, class-conditional image generation.
2021: DALL-E introduced latent autoregressive text-to-image generation, briefly leading the field.
2022: Stable Diffusion's latent diffusion model enabled efficient text-to-image.
Since 2022, latent diffusion has dominated image generation—with Stable Diffusion’s open-source models inspiring creative experiments like the QR code art below.

On Video Generation
2022: Imagen generates high-resolution videos with cascaded diffusion models.
2023: Stable Video adapts Stable Diffusion for video generation.
2024: Sora uses (latent) diffusion transformers for video generation.
2024: Hunyuan also uses latent diffusion transformers, but is open source.
2024: Veo 2 is the latest video generation model, with no public technical details.
The AI videofield is emerging rapidly. In 2024, Sora substantially advanced the state-of-the-art.
And some artists, including shy kids, explored its potential in VFX workflows.
Disclaimer. The views expressed are my own and do not reflect the opinions or positions of my employer.
https://www.youtube.com/watch?v=9oryIMNVtto
Boníssim, porto uns dies fent cançons amb Suno, tinc ganes de provar video fins ara no me'n sortia...