
SAM Audio Explained
Wouldn’t it be cool to separate any audio using a single model?

Meta's new SAM Audio model, explained.
It always felt limiting that general audio source separation models are source-specific.
For example, speech separation models are speaker-agnostic because you don’t want a different model for each speaker in the world. It won’t scale.
Why, then, does general audio source separation need to be source-specific? Why do we need a different model for drums, for guitars, for dogs, or for speech? Wouldn’t it be cool to address general audio source separation with a single model? That’s exactly what SAM Audio aims to do.

SAM Audio separates a target source (one source at a time) based on text, visual, or temporal prompts.
Text: specify what to separate using a description.
Visual: use a visual mask from video frames to indicate what to separate.
Temporal: select an audio region to indicate when to separate.
These modalities can be used independently or together.
Hence, SAM Audio uses a single general model conditioned on text, visual, and temporal prompts, instead of relying on separate source-specific models.
SAM Audio is also generative.
Non-generative (mask prediction) approaches have historically been used for source separation—because they do not “hallucinate”, ensuring that the output strictly reflects the input. They are also typically faster, enabling real-time applications, though they can produce filtering artifacts.
Generative approaches, however, have not historically been used for source separation due to the lack of large training datasets and pre-trained base (generative) models. They are typically slower, which limits their applications, and they can “hallucinate” content.
SAM Audio also uses latent diffusion transformers (DiTs).
Three model variants are considered: small (500M parameters), base (1B), and large (3B). More specifically, SAM Audio trains a flow matching model on large-scale audio dataset covering speech, music, and general sounds.
The model outputs the target source and the residual audio, which are modeled jointly.
It is conditioned as follows:
Mixture, visual and temporal prompts are first encoded into frame-aligned feature sequences, which are concatenated with the noisy latents before being passed into the DiT.
Text prompt is encoded into a global textual embedding with cross-attention layers within the DiT.
Used encoder types:
Visual: Perception Encoder.
Text: T5-base.
Autoencoder is DAC-like but replaces the quantizer (RVQ) with a variational autoencoder (VAE). At 25 Hz with latent size 128.
Temporal span sequences encode whether the target event is silent or active at frame t.
Not all training examples include all three prompt modalities. To handle this, they apply dropout to the conditioning types during training, so each modality can be used independently at inference time.
SAM Audio uses a combination of losses:
A generative loss: the standard flow matching loss.
An alignment loss: that projects intermediate representations into the embedding space of an external audio event detection model.
But most of the work on SAM Audio went into the training data.
The structure of the collected data is (x_mix, x_target, x_residual, conditioning), where the conditioning includes (text, video, temporal span).
Training data comes from two sources:
A large-scale, medium-quality audio–video corpus (≈1M hours).
A collection of small- to medium-scale high-quality audio datasets (≈20k hours).
Where only a small subset includes ground-truth stems for music and speech mixtures.
The rest of mixtures are synthetic: noisy music (music+non-music), speech (speaker+speaker or speaker+noise), and general sounds (audio+audio).
After training with this data, they generate more training data by pseudo-labelling the large-scale audio-video corpus as follows:
Caption dataset to find text-prompts.
Separate mixtures containing multiple sound events with an undertrained SAM Audio version.
Remove low-quality candidates.
Prepare (text, visual, temporal) prompts.
Criteria to filter low-quality candidates:
Low text-audio alignment using CLAP.
Bad audio cleanliness as measured with the “audiobox-aesthetic” model.
Overly silent outputs.
Inisufficient audio-visual correspondence.
Prompts are prepared as follows:
Text: obtained through automatic captioning.
Visual: masks are obtained using SAM3, relying on the text prompt.
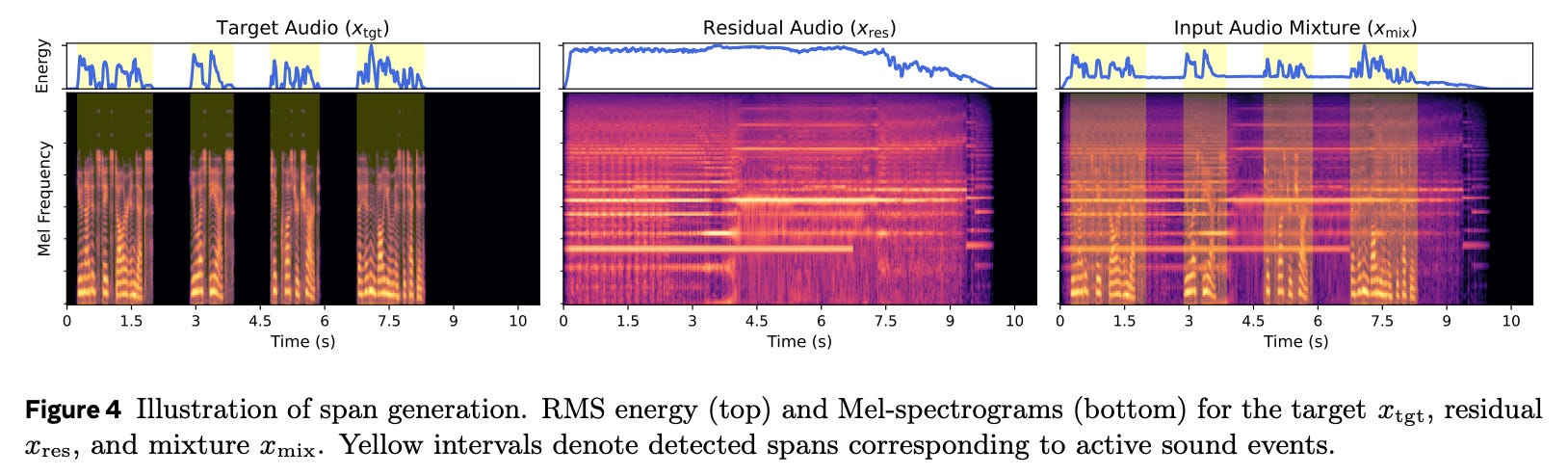
Temporal: select audio regions based on RMS.
This results in ≈1.1k hours of additional training data (out of the original ≈1M hours).
The model is pre-trained on synthetic audio mixtures, while the remaining high-quality data and all pseudo-labeled data are used exclusively for fine-tuning.
Inference uses a 16-step ODE solver without classifier-free guidance. They run 8 different separations and select the best.
Temporal Span Clarification
The temporal span prompt is a bit unusual.
It appears almost like a “cheat code” that tells the model exactly when to separate—rather than learning both what and when to separate. Providing the temporal span allows the model to focus solely on what to separate.
It is encoded as a sequence, where each frame is marked as either active (in yellow below) or not.
Disclaimer. The views expressed are my own and do not reflect the opinions or positions of my employer.